code release and redundancy
Message boards : Number crunching : code release and redundancy
| Author | Message |
|---|---|
|
David Baker Volunteer moderator Project administrator Project developer Project scientist Send message Joined: 17 Sep 05 Posts: 705 Credit: 559,847 RAC: 0 |
I see from recent discussions on the message boards that there are serious concerns about code release because of the possibilities for cheating in gaining credits. We thought it would be good to give out the code because we thought 1) people would be interested in seeing it, 2) compilation and code performance on a much wider array of platforms than we have in house could be optimized and 3) experts could experiment with variations on search strategies. But because of the many concerns I am reconsidering this--keeping all of you happy is clearly critical! It would be good to have an idea of how many are in favor and how many are against code release in the current setup. I've argued against redundancy in the past because it is a waste of resources. But perhaps we should go to two fold redundancy because of the credit issue. How about this: when we get to 1,000,000 credits per day, we go to two fold redundancy and give out the code. (Anybody want to place a bet on when we break the 1,000,000 a day mark?) I like the following suggestion, if we can do this it would be a good solution and avoid the need for redundancy. "BOINC V5.x has the SETI-beta "flop counting" code in it. Using that would both eliminate cheating-via-benchmarks, and would be a good example of the "improved" method for other projects to follow." what do people think? |
|
EclipseHA Send message Joined: 3 Nov 05 Posts: 12 Credit: 284,797 RAC: 0 |
If you're looking for bug fixes, relase the code only to those that will provide fixes back to you to be included into the "standard clients" and won't be distruting untest crunchers. If you want more platforms, again, give it only to people that will provide the project with a tested version that can be released thru normal means, and not allow "untested crunchers" to be freely distributed. With the exception of Seti, all projects restrict the release of their source code, and I think this project should do the same. I think the question back to the project should be "Why do you want to allow unlimited access to the source code for your crunching code?" |
|
Ethan Volunteer moderator Send message Joined: 22 Aug 05 Posts: 286 Credit: 9,304,700 RAC: 0 |
Is it possible to somehow integrate a security function into rosetta that would allow you to open source it, but keep people from falsifying results? Such a function would prevent users from creating their own distributions, but it would allow programmers to suggest optimizations in the code. You could then assemble the scientific code in house, add the security function, and release a new version of the work units. Say you're doing 10 simulations in a work unit. Each has a calculated RMS value. You could use a hash that compares the values returned by the scientific code (result1 + 10result2 - 1/3result3 etc). If you keep the hash private that verifies a work unit, it should be very hard to fake a result. |
 Tern TernSend message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
Since the flop-counting comment was mine, I obviously like that part... :-) However, be aware that it ONLY stops the cheating-via-benchmarks; there are other ways to cheat IF the code is open source. (And talk to Paul D. Buck - he may have other concerns about that method.) In spite of that, I do vote for releasing the code, with one caveat - don't "do a SETI" and then just ignore what everyone does with that code. When someone has a well-optimized version for AMD/Windows, or Mac, or whatever, roll those changes back into your own code stream. If someone compiles a version that "cheats" on credits, well, too bad. If they compile a version that cheats the SCIENCE, when you detect it, throw them out, and fix the validator to detect what that code was doing, and make those results invalid. Hopefully, the things that will be looked at by outside developers, other than speed, are the percent-complete reporting, and the problem with being swapped out of memory... On redundancy - I see no reason at this time to do it. There are just more important uses for the power. Doing it when you hit a million a day sounds fine. I would run some reports every so often to see if any participants are requesting "well above average" credits on every WU, however! 
|
|
David Baker Volunteer moderator Project administrator Project developer Project scientist Send message Joined: 17 Sep 05 Posts: 705 Credit: 559,847 RAC: 0 |
If you're looking for bug fixes, relase the code only to those that will provide fixes back to you to be included into the "standard clients" and won't be distruting untest crunchers. I like this suggestion, but how do we actually do this in practice? |
|
FZB Send message Joined: 17 Sep 05 Posts: 84 Credit: 4,948,999 RAC: 0 |
i am strongly interested in seeing/learning from/improving the code (studying bioinformatics right now and been around programming for a living before for some years) and would have no problem with signing some kind of NDA (wouldn't be the first anyway ;) ). the NDA approach is good as have some control over the app while it is bad as you have to manage user requests and so on. i have not read into the flop_count thing but if it actually counts the used op's at a reasonable performance hit i guess it wouldn't hurt just to be on the safe side. giving source not out because of cheating is a valid concern, though i think in the end (at least atm) you can already cheat with faked benchmarks in a customized boinc manager, so not sure how big an "cheat" impact it would really be. maybe run a cron job once a week and check the db for claimed credit spikes, if they are from a single user and that user uses a custom rosetta app, you could still investigate. -- Florian www.domplatz1.de |
|
Hoelder1in Send message Joined: 30 Sep 05 Posts: 169 Credit: 3,915,947 RAC: 0 |
I for one would probably leave the project if I knew that the exact same work my computer was doing is duplicated be someone else. It feels like being distrusted and that my contribution is not really needed. Your suggestion to go to twofold redundancy when 1,000,000 credits per day are reached also suggests to me that the project doesn't really need that much computing power, another reason to leave the project at that stage. Also, regarding the cheating issue, since currently the gained credit is donated CPU time x benchmark rating, it isn't possible to get more credits by tinkering with the rosetta code, or am I missing something here ? So why should giving out the rosetta code be an issue as far as cheating for credits is concerned ? Since the energy can easily be re-calculated from the returned structure I also don't see why redundancy should be required to detect invalid results. -H.B. |
|
David Baker Volunteer moderator Project administrator Project developer Project scientist Send message Joined: 17 Sep 05 Posts: 705 Credit: 559,847 RAC: 0 |
Even with the progress of the last two days, it is clear we are going to be CPU time limited for the forseeable future. So redundancy really is wasteful. How would people feel about this: we do not resort to redundancy, so every calculation is unique, but we wait to release the code until the credit issue is resolved. |
|
Scribe Send message Joined: 2 Nov 05 Posts: 284 Credit: 157,359 RAC: 0 |
I concur withyour last post David.  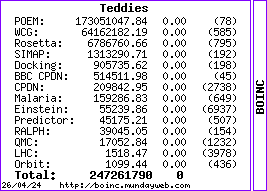
|
|
AnRM Send message Joined: 18 Sep 05 Posts: 123 Credit: 1,355,486 RAC: 0 |
I think that not releasing the your code would be very prudent at this stage. I remember the problems classic SETI had and also I believe that P@H was hit with a virus some time ago. Why make yourself more vulnerable to these problems? |
|
Desti Send message Joined: 16 Sep 05 Posts: 50 Credit: 3,018 RAC: 0 |
Sounds good. What license will Rosetta use? LUE |
|
stephan_t Send message Joined: 20 Oct 05 Posts: 129 Credit: 35,464 RAC: 0 |
David, On opening the code -------------------- I think you need to accurately measure, not guess, the predicted ammount of contributions you'll get from opening your code. There are not many people out there who are programmers. A fraction of those are good programmers able to contribute something worthwhile on something like Rosetta. And only a tiny fraction of that minority understand a thing or two about the science involved. How many are registered Rosetta users? You just need to have a look at sourceforge.net to see where I'm going with this idea. Most F/OSS projects there are led by the original programmers, and never receive any valuable contribution from their users. Instead people just download those programs as 'freewares'. So, IMHO, you might be a little bit too optimistic about your chances to get something valuable out of opening your code. Why not parametize the program to let the science experts 'play' with the application instead? On cheating ----------------- As for the cheating aspect, I'm confused - I thought the credit was linked to the BOINC manager, not the project itself. Obviously people are already cheating via benchmarks, and it's rumored that some could cheat via using modified boinc code. I say 'could' because I have yet to see 1) a user accused of cheating 2) a user banned from having cheated 3) counter measures to prevent cheating. Make no mistake about it, undetected cheating may pass as 'ok' for now, but if it was to become public that widespread cheating took place, the 'competitive' users would go - and fast. I have this hunch that the 'masses' of single cpu users crunch because they like the pretty screensavers - or in your case are boinc users who enjoy attaching to yet another project. The top 500 users though, spend a lot of time making sure their machine crunch as effectively as possible for as long as possible - from experience I can tell you it takes a lot of efforts to do so... and I can imagine how disapointing to see rogue user cheat and take credit instead - it would simply ruin the fun. On redundancy ------------------- That doesn't bother me - as long as 1) I stil get my credit and b) it efficiently helps the science (ie, is not 'wasteful') On flop counting ------------------- Whatever helps reduce the number of cheaters is good. As somebody else pointed out, Paul D. Buck has made a lot of research in that field, it would be great to have his opinion. Team CFVault.com http://www.cfvault.com 
|
|
Fuzzy Hollynoodles Send message Joined: 7 Oct 05 Posts: 234 Credit: 15,020 RAC: 0 |
First, I agree with David's last post. For fiddling about with benchmarks just read this thread! And I don't think this is the only example. [b]"I'm trying to maintain a shred of dignity in this world." - Me[/b] 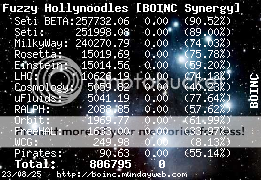
|
|
Paul D. Buck Send message Joined: 17 Sep 05 Posts: 815 Credit: 1,812,737 RAC: 0 |
Ok, Paul's Opinion ... for what it is worth ... :) 1) Credit is important. 2) Integrity of the results is important. Anything that compromises those should not be done. :) I am on the fence on opening the source. I see the advantages of the POTENTIAL of having other people look at the code and who try to work with it to make improvements. SETI@Home *IS* having luck with a half-dozen people working with the code and coming up with suggested optimizations. Some of that work *IS* being incorporated (though I am not at all clear how much is being absorbed into the baseline code). So, this CAN work. However, with the code in the "wild", it is also being compiled into clients that are not "standard" in that they are using code that is not part of the baseline. Since SETI@Home is not "real" science, well, this matters little. I can't get that excited about it ... However, (pronounced "HOWEVER COMMA" in a deep bass voice ... sorry ... an old "Paulism" joke) Rosetta@Home is not "junk" science. With that in mind I have serious reservations about "wild" code. I cannot remember if the work returned can be "signed" to prevent the use of an unapproved binary, but I do not believe that this is a possibility. Thus, I would not recommend that the code be opened up (yeah, I changed my mind). Adding optimizations to the compile process can be done with closed source, and Einstein@Home has, in fact, done this ... The only way to allow open compiles/open source and to prevent compromise of the science is to then use redundency. Which gives an immediate reduction in resource of 50% or MORE. Also a bad outcome. If more "eyes" are desired, well, NDA may be the best of the "bad" ways to do this. Since you are likely to only have a few people actually look at it ... well ... this is one way to go ... (I mean, even if I did look at the code, my first thought would be to ask why you did not select a "real" programming language ... but, that too is a personal opinion ...) Conclusion: Paul votes *NO* on the release of the source code. ==== Credit: Cheating is already going on. There has been at least one person that compiled a client that output what that person "thought" the benchmark "should" output as a value. Perfectly legitimate under the current "rules". But, is this what we should allow? We have, under the current system: 1) a variance of up to 100% between credit claims for the same work unit, all under the same OS. 2) A variance between HT and non-HT processors 3) Instability in benchmark results to 100's of FLOPS (an inaccuracy that exceeds 10%) 4) No validation that the system has not been compromised 5) No validation that the claims have not been forged, altered, compromised, inflated, etc. With *ALL* of that in mind, until we use a credit claim system that has safeguards in place projects such as Rosetta@Home are at severe risk to credit "games". The only safeguard currently in place requires redundency of 3 or greater to provide partial protection (redundency of 4 or more is actually required for reasonable confidence). Even so, I proved that you could, with no serious intent to "cheat", dramatically change your credit "posture" quite simply. Even my proposal would still require spot checks, though, without data I cannot say for sure that the system might not be sufficient with minor modifications. That is the problem with a new proposal you cannot be sure of actual performance until you actually begin to use it ... Conclusion: We need an improved credit system. And the upcoming FLOPS counting tool, in and of itself, will *NOT* be sufficient to improve the credit system. Other changes will *NOT* occur unless coded by a third party, *OR* projects begin to demand an improved system. The reason for that last is that the participants have been asking for an improved system since the BOINC BETA Test with no response from UCB. I had *HOPED* to be working on my own proposal by now. Bad news is that about all I am able to do these days is to partrol the boards once each day ... after that I am shot ... ==== Edit: David, sorry, but you need to read the proposal I wrote to really see how bad the Credit system is ... I do not mind debating the topics here ... but I am also amenable to discussing anything with you by e-mail ... p.d.buck@comcast.net (assuming you see value in my opinions). |
|
stephan_t Send message Joined: 20 Oct 05 Posts: 129 Credit: 35,464 RAC: 0 |
|
|
stephan_t Send message Joined: 20 Oct 05 Posts: 129 Credit: 35,464 RAC: 0 |
V. interesting post Paul. Thanks for that - I hope the BOINC team will take your comments on board. Regarding the cheating issue by modifying the client (fixed bench number), I'm suprised we aren't already at the point where the top 10 participants is made of names like 'LOLROX0row3d' with scores of 30 billion +. Surely if someone already done that, we would have seen him/her at the top of the credit ladder. Team CFVault.com http://www.cfvault.com
|
|
Tern Send message Joined: 25 Oct 05 Posts: 576 Credit: 4,702,007 RAC: 0 |
If more "eyes" are desired, well, NDA may be the best of the "bad" ways to do this. Since you are likely to only have a few people actually look at it ... well ... this is one way to go ... (I mean, even if I did look at the code, my first thought would be to ask why you did not select a "real" programming language ... but, that too is a personal opinion ...) I for one would be willing to sign an NDA, and take a look at the code to see if there are any areas where I could come up with ideas for improvement - but I would agree with Paul on the language issue, and I would not claim to be able to _fix_ any problems I found, only report them. I have been programming for 25+ years, but when it comes to C and it's derivatives, I'm limited... probably 90% of any "bugs" are directly related to inadequacies in the language itself, that proficient C programmers know to "work around" - and those I would be unable to spot. Algorithmic or logic problems, I think I could locate. It's been a while since I've tortured myself trying to read C, so I might survive the attempt! To address the questions on "what difference does open-source on the application make to credits", well, using the current benchmark*time approach, controlled by the BOINC client, there's only one way that I can think of, that I won't reveal as it may give someone ideas. However, if the flop-counting approach is used, as I believe it should as the bare MINIMUM, given no redundancy, I can think of several ways. There are definite advantages to open source, azwoody's complaints aside - but there are disadvantages as well. Under the "once released can't be taken back easily" rule, and since outside help is being considered under NDA or whatever, I suppose I vote for keeping it closed at the moment - so please reverse my earlier "open it" vote. I don't think cheating is, or is likely to be soon, a "major issue". Sure, there are those who are probably right now requesting 25-50% "too many" credits per result, either out of a desire for the "credits" or simply because they're running an "unreasonably" optimized client to match a SETI optimized app. I am in that situation myself - running Trux 5.3.1 on the AMD with YAOSCW. On SETI, I'm requesting exactly in the middle of the quorums; on Rosetta, I'm high compared to others. I'm about to fix this by removing SETI and 5.3.1 on that PC and making Rosetta it's major project. I don't think anyone in the "top 100" on any project is there today because they are drastically cheating; when that happens, then it'll be "too late" to deal with it - so it would be nice to prevent it soon, but not (imho) critical yet. I love Paul's calibrated-host proposal, but I'm not sure if Rosetta could do that on it's own without UCB involvement; flop-counting is already "there" to be used, and while not perfect, it's at least more difficult to cheat. I think there are more important issues with the Rosetta source however, primarily in the %-complete reporting, and in the slower-than-it-should-be Mac version. As for the 1-million-credit-per-day level; David, you DO realize that Rosetta was over a half-million yesterday? I don't know the trend of how fast it's been growing, but I'm betting the million mark is reached sooner than you think. My bet is January. :-)
|
|
Scott Brown Send message Joined: 19 Sep 05 Posts: 19 Credit: 8,739 RAC: 0 |
I agree with most here regarding concerns over completely releasing code into the 'wild'. However, we should not forget (as Paul briefly mentioned), the benefits that have come from optimized SETI code. Quite simply, optimized clients have produced up to double throughput levels for some machines. Given Rosetta's inherent need for increased CPU power, such increased throughput is fundamentally important. Thus, I would suggest that a modified open release occur. Specifically, release the code into the wild with a standard test workunit available. Optimized clients could then be created and submitted back to Rosetta for approval. Rosetta would then, upon approval, provide the optimized client through the official website only. Put an official Rosetta signature on these clients such that any unsigned clients would not be validated. This does not address the concerns with cheating, however. Cheating by gaming benchmarks (or FLOP counts, etc.) would still be possible since such measurss are produced by the BOINC core which could be unofficially optimized to return absurdly high values for these. I can see only two solutions to this problem: 1) Rosetta could lobby/demand that the UCB staff create a similar 'official stamping' process for optimized BOINC cores or 2) What Paul said...redundancy is required. |
|
DaffyDJ Send message Joined: 17 Sep 05 Posts: 157 Credit: 2,687 RAC: 0 |
I think the code should be released it may attract more people to the project for a start and it should be made to verify results twice there is always people going to think about others cheating whilst the results aren't verified Join us in Chat (see the forum) Click the Sig  Join UBT |
|
Janus Send message Joined: 6 Oct 05 Posts: 7 Credit: 1,209 RAC: 0 |
Ok, several things: 1) Security through obfuscation doesn't work. Period. Going closed source in attempt to avoid having people manipulate/fake results is exactly what will make people do these kinds of things. If redundancy is >=2 they can't get their results validated and hence there's no idea in attempting to cheat the system. 2) Furthermore closed source still allows people to set artificially high claimed credit values for their work, repetitively returning the same or similar looking results or something like that - Unless the redundancy is at at least 2. 3) I've learned that in science an independently confirmed result is worth at least twice as much as a result that cannot be fully trusted. 4) Most of the applications that are compiled on my own machine will run between 10 and 50% faster compared to the a standard x86 version - simply because the GCC or ICC compilers have nifty optimizations for mostly every CPU on earth. Those optimizations don't break the code and will provide the exact same results but utilize special features on the CPU to gain speed. Setting redundancy to 2 while at the same time releasing the source code therefore does not equal a 50% drop in overall crunching power. 5) Even with closed source you will encounter people with CPUs so overclocked that the result is utterly wrong. With redundancy this result will be dropped. Also there's a small difference in how platforms handle floatingpoint operations. This can cause the results to differ across platforms. Without redundancy you may never know of some strange bug only apparent on a single odd platform. If I remember correctly a couple of other projects had to rewrite their science code after seeing that the results from different platforms didn't match up at all. --- Given the current influx of users, the current credit rate and climbing RAC, it probably won't be more than a month or two before you hit an RAC of 1000k (it's 560k right now and I haven't even started yet, hehe). "Live" Rosetta RAC based on last XML export --- Well, I'd say do what the title of this thread says ("code release and redundancy"): Go for the reliable results (redundancy=2 or higher) AND Release the code to get the results faster (and help optimizers by providing a test-WU+result and telling what limits for the values are accepted) It's your call though. No matter what you choose you are probably going to loose a bunch of users who disagree in your decision. Tuff one eh'? ps. If you know exactly how many iterations are spent in each loop of the science app you can use the most precise of the credit measurement systems in BOINC. But it takes a little while to actually figure that stuff out... CPDN can do it this way because they have an app that always spends the same amount of cycles in particular loops. pps. Oh, one thing about redundancy=2: It is conservative credit-wise. You will always get granted at most the amount of credit that you deserve. Some people tend to dislike this... I find it way more fair than the current "get whatever you like" credit strategy. |
Message boards :
Number crunching :
code release and redundancy

©2026 University of Washington
https://www.bakerlab.org