Help us solve the 1% bug!
Message boards : Number crunching : Help us solve the 1% bug!
Previous · 1 . . . 3 · 4 · 5 · 6 · 7 · 8 · 9 · Next
| Author | Message |
|---|---|
|
afarensis Send message Joined: 27 Jan 06 Posts: 1 Credit: 66,012 RAC: 0 |
CPU type GenuineIntel Intel(R) Pentium(R) D CPU 3.20GHz Number of CPUs 2 Operating System Microsoft Windows 2000 Professional Edition, Service Pack 4, (05.00.2195.00) Memory 1023.17 MB Cache 976.56 KB Swap space 2462.37 MB Total disk space 76.33 GB Free Disk Space 72.46 GB Measured floating point speed 1940.9 million ops/sec Measured integer speed 3111.62 million ops/sec Problema dell'1% dopo ore - 05:06:52 WU: FA_RLXfk_hom005_1fkb__360_235 LINK: https://boinc.bakerlab.org/rosetta/workunit.php?wuid=11270 530 |
|
doc :) Send message Joined: 4 Oct 05 Posts: 47 Credit: 1,106,102 RAC: 0 |
2nd stuck @ 1% on my main pc within 1 week, never had any of those for months of crunching on this host. WU - result (still running while i type this) was stuck at step 25958 of model 1 for about 20 minutes (was taking a look at the graphics, otherwise it would have run for longer before i noticed), exited and restarted boinc twice and it is stuck at the exact same step again each time, got it suspended for now. i will abort it if i hear no further instructions before monday evening cet. |
|
David Baker Volunteer moderator Project administrator Project developer Project scientist Send message Joined: 17 Sep 05 Posts: 705 Credit: 559,847 RAC: 0 |
Hello. Earlier I had my first 1% bug after processing many work units with little or no problems. Yes! conflict between threads seems to be the source of a significant fraction of the problems, and it is indeed not reproducible--Rom has some fixes which seem promising, and hopefully we will have a lot of the problems resolved soon. |
|
Hans Schulze Send message Joined: 20 Dec 05 Posts: 7 Credit: 102,405 RAC: 0 |
2006-03-17 6:55:43 AM|rosetta@home|Starting result FA_RLXnp_hom022_1npsA_361_221_0 using rosetta version 482 2006-03-17 4:18:04 PM|rosetta@home|Result FA_RLXnp_hom022_1npsA_361_221_0 exited with zero status but no 'finished' file 2006-03-17 4:18:04 PM|rosetta@home|If this happens repeatedly you may need to reset the project. 2006-03-17 4:18:04 PM||request_reschedule_cpus: process exited 2006-03-17 4:18:04 PM|rosetta@home|Restarting result FA_RLXnp_hom022_1npsA_361_221_0 using rosetta version 482 Now stuck at 1%, 10:49 PM, no graphics activity, step 21585. Suspend, resume, no effect. Exited Boinc, restarted, the thread ran to exactly the same spot and stopped in about 15 seconds. I permanently suspended that wu, and now my machine is working on the next one while I look at why it stops. Strangely enough, the suspended wu is still hogging 100MB of ram. Running the same job with the same seed passed the 1% point no problem. I must say that I don't like that my machine crunched for 9+6.5 hours with no result or credits. Boinc should definitely not restart the calculation without notifying HQ. Is it possible that some files were copied incorrectly as the job was started? I will save this post, reboot, resume, and post back here if it ran correctly under the GUI. |
|
Hans Schulze Send message Joined: 20 Dec 05 Posts: 7 Credit: 102,405 RAC: 0 |
FA_RLXnp_hom022_1npsA_361_221_0 using rosetta version 482 After rebooting the system, this calculation stops in the same place. Archived (RAR) the slot directories, deleted them all, and restarted the wu, it still hangs in the same place. Exited Boinc, restarted it, got the graphics on the screen, then quickly killed both Boinc and Boincmgr. The graphics continued flawlessly. Not sure what happened next, but that wu disappeared without completing. I will try this again next time I see a wu puddle. |
|
Laurenu2 Send message Joined: 6 Nov 05 Posts: 57 Credit: 3,818,778 RAC: 0 |
This thread is approaching 100 posts - Is the project ANY closer to solving the 1% bug? Yes This what I would like to know "" ANY closer to solving the 1% bug?"" I have had to abort about 10 WU's stuck at 1% For a loss of about 300 Hrs of coumpter time in just the past week. Maybe a auto self abort if it go's past 3 times the limit People like me some times can not check up on all the nodes every day, and to let a WU run for 114 Hrs is just a waste of time and Money I do not work in IT and I pay for the total cost to run DC If You Want The Best You Must forget The Rest ---------------And Join Free-DC---------------- |
 Angus AngusSend message Joined: 17 Sep 05 Posts: 412 Credit: 321,053 RAC: 0 |
What do you have to offer those of us with large unattended farms? If the WU goes past 2 or 3 times the user's selected run time, why not abort it? If I see it, that's what I'm going to do manually. One WU lost is not going to make any difference to the science, and we don't have the issue of holding up credit awards. Chances are very good it's a 1% problem, not some big ooglie new type of WU. Those big new ooglie things should probably have a hard lower limit for run time that overrides the user preference to get at least one model crunched. I doubt many serious crunchers are going to be watching cycle-sucking screen savers... those are for the SETI LGM searchers. Most will only be running boinc.exe in CLI mode, and monitoring perhaps with BoincView. Proudly Banned from Predictator@Home and now Cosmology@home as well. Added SETI to the list today. Temporary ban only - so need to work harder :)  "You can't fix stupid" (Ron White) |
|
Laurenu2 Send message Joined: 6 Nov 05 Posts: 57 Credit: 3,818,778 RAC: 0 |
This thread is approaching 100 posts - Is the project ANY closer to solving the 1% bug? The WU's I aborted were at a min 11Hr and that was only by luck the others were about 30 55 77 85 114 Hrs I see no reason why you would want a WU to work past 30Hrs when it should be 2 Hrs I could have done 50 WU's in the time it took me to abort that one 114 Hr WU It seems you you are having problems fixing the 1% problem And thats OK BUT you have to give us a some kind of temporary fix to this problem A time limit, a top end, something to stop it from wasting computer time that can go into the hundreds of Hrs. As for restarting the WU I my self have lost faith in that WU and I really do not want to rerun it or WASTE any more time with it I do feel for sorry Rosetta is having troubles with this But Rosetta also should feel sorry that we crunchers have to pay the troubles If You Want The Best You Must forget The Rest ---------------And Join Free-DC---------------- |
|
BennyRop Send message Joined: 17 Dec 05 Posts: 555 Credit: 140,800 RAC: 0 |
According to Rom's blog at http://www.romwnet.org/ the 1% problem is the next on his list. If it takes him more than a week to track down the problem and cure, would it be possible to have Rosetta's jobs terminated if they're still at 1% after 8 hours? Or is it possible to have a remote program like BoincView monitor for that situation, and remotely terminate and restart Rosetta automatically? |
|
UBT - Timbo Send message Joined: 25 Sep 05 Posts: 20 Credit: 2,306,580 RAC: 0 |
But there are more users that are not farmers and that is why I suggest people use the Display function to look at the graphic. But, if like me, you've installed BOINC as a service, the display option is NOT available. I've had to re-install BOINC as a single-user, in order to figure out why Rosetta was messing around and failing to complete WU's. (Luckily, I'm very PC literate, so this wasn't a problem - but for some newbies, who have joined this project and THINK they are doing useful work - for them, this could be a real deal breaker, if the project doesn't sort itself out - although with Rom doing his bit now, I have much greater faith that this will be resolved soon). In the meantime, like others, I've lost faith in any new work that I might download and have now suspended Rosetta and am crunching more for other projects as a result, as I'm not keen on wasting the processing power at my disposal - it's not a lot, but the reason for joining BOINC was to make my PC do work, while the CPU was idle. And having it run Rosetta and not generating useful results is a worse scenario that not having BOINC installed in the first place...! In the meantime, I am going to have to suspend our "Weekend Crunch" next weekend in favour of Rosetta and we'll have to switch our crunching power over to another project, as I cannot accept responsibility for my team to be crunching for a project that cannot provide work units that are consistantly able to be returned. We'll be back supporting you when you have a solution (which I'm sure will happen soon, but maybe not in time for 25th-26th March ! ) regards, Tim |
|
Scribe Send message Joined: 2 Nov 05 Posts: 284 Credit: 157,359 RAC: 0 |
https://boinc.bakerlab.org/rosetta/workunit.php?wuid=11090083 Stuck at 1% for over 18 hours....I was away for the weekend and it had failed when I got back!  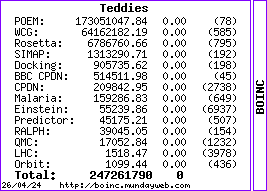
|
|
bruce boytler Send message Joined: 17 Sep 05 Posts: 68 Credit: 3,565,442 RAC: 0 |
Hi All, Had a workunit stuck at 1% for over 40 hours. It was part of the new fa workunits. Brought up the graphics and the cpu time was running but all the picture areas were frozen at whatever point the bug appeared. Tried resetting the BOINC Manager sometimes this helps but in this case it did not. I ended up havin to abort it. It droppeded off my results before I could get back and write which workunit it was. Also got 7 "20 second errors" out of 175 results. Have 1 gigbyte AMD 3800+ x2 processor. Cheers........... 
|
|
Hans Schulze Send message Joined: 20 Dec 05 Posts: 7 Credit: 102,405 RAC: 0 |
I don't mind an occasional error, but I do have a few issues 1) Why restart a unit that already overran time? I happened to notice this message in the log. I don't see how I get credit for the restart, as the CPU time is zeroed, and no additional communications happens with R@H. 2) Cancelled unsuccessful units seem to be recycled for some other oaf to run, so the number of these units floating around is increasing. After 3 failures by different people, they should be cancelled and permanently removed from the database queue. 3) This was reported half year ago, and doesn't seem to be serious enough to already be under active research 4) Suspending a WU seems to restart the CPU time, and hence credits. Pausing the WU's to swap also seems to zero the before-stop cpu time, and hence credits 5) There is no local persistant log of either error messages, or of completed wu's so it is hard to tell what went wrong before Microsoft's last update or company policy mandated machine update/patch restart. I would recommend appending to the existing log on Boinc restart. We need the logs to figure out the pattern here. 6) One of my machine bluescreens (bad pool caller) since I have installed Boinc - had run Seti for almost 2 years on that machine before that with no issues. Will run diags and reinstall drivers, but with Boinc causing some R@H to calculate WUs differently, who knows what's wrong. I ran Seti in the days |
|
Snake Doctor Send message Joined: 17 Sep 05 Posts: 182 Credit: 6,401,938 RAC: 0 |
I don't mind an occasional error, but I do have a few issues If you abort a WU, the number of WUs available to your system for downloading decreases. If you abort a lot of them before you start returning successes you could force the server to stop sending you any work. If you restart the WU, while it may not give you the full credit based on the "hang" time, it will return some credit if it runs and it will not reduce your download possibilities. Regards Phil  We Must look for intelligent life on other planets as, it is becoming increasingly apparent we will not find any on our own. |
|
Hans Schulze Send message Joined: 20 Dec 05 Posts: 7 Credit: 102,405 RAC: 0 |
I just found another workunit that restarted several times, wasting the whole day on an AMD 3500+ machine. 2006-03-19 7:40:03 PM|rosetta@home|Restarting result FA_RLXct_hom018_1ctf__360_252_1 using rosetta version 482 This is the 7th so-called 1% I get in a week. Sorry, but I will remove this application from my farm. |
|
Dutch Power Chicken Send message Joined: 14 Dec 05 Posts: 1 Credit: 537,491 RAC: 0 |
I've got two WU's sticking at 1%: FA_RLXdh_hom001_1dhn__360_263_0 (running for 39:29:49 hours) FA_RLXli_hom020_1lis__361_263_0 (running for 26:52:58 hours) |
|
Nite Owl Send message Joined: 2 Nov 05 Posts: 87 Credit: 3,019,449 RAC: 0 |
Here's a WU that wasted 105.9 hours before I noticed it in BOINCView.... Checked the Graphics, no discernible movement observed. I suspended the WU ,restarted it with no joy. Exit from BOINC, restarted BOINC still no joy... Aborted WU. Did I mentioned it wasted 105.9 hours? <grrrrrr> FA_RLXey_hom011_1eyvA_360_160_0 , Result ID 13903946, Work unit 11233006, Computer ID 56899, CPU time 381298.796875. stderr out <core_client_version>5.2.13</core_client_version> <message>aborted via GUI RPC </message> <stderr_txt> # random seed: 2665711 # cpu_run_time_pref: 36000 </stderr_txt>  |
|
David Baker Volunteer moderator Project administrator Project developer Project scientist Send message Joined: 17 Sep 05 Posts: 705 Credit: 559,847 RAC: 0 |
Please--if you have frequent occurrences of the 1% bug--it would help us enormously to solve it if you could sign up for RALPH@home. Rom can then identifiy the exact lines of code where the problem is ocurring and it will be easy to fix from there. the problem is that many machines don't have this problem, and they can't help us to track it down and solve it. |
|
Nite Owl Send message Joined: 2 Nov 05 Posts: 87 Credit: 3,019,449 RAC: 0 |
Please--if you have frequent occurrences of the 1% bug--it would help us enormously to solve it if you could sign up for RALPH@home. Rom can then identifiy the exact lines of code where the problem is ocurring and it will be easy to fix from there. the problem is that many machines don't have this problem, and they can't help us to track it down and solve it. The problem is it doesn't necessarily happen a lot on all machines. I don't think I've ever two on the same puter. I already have a machine (computer # 1947) crunching Ralph WUs, and its had 11 failures of 40 downloaded but no 1%ers. I ran Ralph on another machine (computer # 317) and ran 19 WUs (when it could get one) without a problem... But that doesn't help with the other 29 machines. They have completed 43 WUs today 20th with 6 failures including the one I aborted for the 1% error. |
|
Nite Owl Send message Joined: 2 Nov 05 Posts: 87 Credit: 3,019,449 RAC: 0 |
I just did a ramdom check on the rest of my computers and found a common problem that most of them has experienced at one time or another: Result ID 12869089 Name HOMSdt_homDB030_1dtj__352_802_0 Workunit 10345130 Created 7 Mar 2006 14:32:01 UTC Sent 8 Mar 2006 1:45:20 UTC Received 8 Mar 2006 1:49:41 UTC Server state Over Outcome Client error Client state Computing Exit status 1 (0x1) Computer ID 142185 Report deadline 22 Mar 2006 1:45:20 UTC CPU time 25.890625 stderr out <core_client_version>5.2.13</core_client_version> <message>Incorrect function. (0x1) - exit code 1 (0x1) </message> <stderr_txt> </stderr_txt> Validate state Invalid Claimed credit 0.165637012638972 Granted credit 0 application version 4.82 |
Message boards :
Number crunching :
Help us solve the 1% bug!

©2026 University of Washington
https://www.bakerlab.org